1、概述
Lemon是一个LALR(1)文法分析器生成工具,与bison和yacc类似,是一个可以独立于SQLite使用的开源的分析器生成工具。而且它使用与yacc(bison)不同的语法规则,可以减少编程时出现错误的机会。Lemon比yacc和bison更精致、更快,而且是可重入的,也是线程安全的——这对于支持多线程的程序是非常重要的。
Lemon的主要功能就是根据上下文无关文法(CFG),生成支持该文法的分析器。程序的输入文件有两个:
(1) 语法规则文件; (2) 分析器模板文件。 一般来说,语法规则是由程序员定义的;Lemon有一个适用于大多数应用程序的默认分析器模板。根据命令行选项,Lemon会生成以下一些文件:
(1) 分析器的C代码; (2) 一个为每个终结符定义一个整型ID的头文件; (3) 一个描述分析器状态的文件。语法规范文件以”.y”为后缀,如果语法规范文件为”gram.y”,则可以使用该命令生成分析器:lemon gram.y。
1.1、分析器接口
Lemon不会生成一个完整的、可以运行的程序。它仅仅生成一些实现分析器的子例程,然后由用户程序在适当的地方调用这些子例程,从而生成一个完整的分析器。
1.1.1、ParseAlloc
程序在使用Lemon生成的分析器之前,必须创建一个分析器。如下:void *pParser = ParseAlloc( malloc );
ParseAlloc为分析器分配空间,然后初始化它,返回一个指向分析器的指针。SQLite对应的函数为:
void *sqlite3ParserAlloc(void *(*mallocProc)(size_t))
函数的参数为一个函数指针,并在函数内调用该指针指向的函数。如:
void *sqlite3ParserAlloc(void *(*mallocProc)(size_t)){ yyParser *pParser; pParser = (yyParser*)(*mallocProc)( (size_t)sizeof(yyParser) ); if( pParser ){ pParser->yyidx = -1;#ifdef YYTRACKMAXSTACKDEPTH pParser->yyidxMax = 0;#endif#if YYSTACKDEPTH<=0 pParser->yystack = NULL; pParser->yystksz = 0; yyGrowStack(pParser);#endif } return pParser;} 1.1.2、ParseFree
当程序不再使用分析器时,应该回收为其分配的内存。如下:ParseFree(pParser, free);
SQLite对应的函数如下:
void sqlite3ParserFree( void *p, /* The parser to be deleted */ void (*freeProc)(void*) /* Function used to reclaim memory */){ yyParser *pParser = (yyParser*)p; if( pParser==0 ) return; while( pParser->yyidx>=0 ) yy_pop_parser_stack(pParser);#if YYSTACKDEPTH<=0 free(pParser->yystack);#endif (*freeProc)((void*)pParser);} 1.1.3、Parse
Parse是Lemon生成的分析器的核心例程。在分析器调用ParseAlloc后,分词器就可以将切分的词传递给Parse,进行语法分析。SQLite对应的函数如下:void sqlite3Parser( void *yyp, /* The parser */ int yymajor, /* The major token code number */ sqlite3ParserTOKENTYPE yyminor /* The value for the token */ sqlite3ParserARG_PDECL /* Optional %extra_argument parameter */)
该函数由sqlite3RunParser调用:
int sqlite3RunParser(Parse *pParse, const char *zSql, char **pzErrMsg)
sqlite3RunParser位于token.c文件中,它是进行SQL语句分析的入口,它调用sqlite3GetToken对SQL语句zSql进行分词,然后调用sqlite3Parser进行语法分析。而sqlite3Parser在语法规则发生规约时调用相应的opcode生成子例程,生成opcode。
1.2、与yacc和bison的不同之处
Lemon与yacc和bison有一些不同的地方:
(1)在yacc和bison中,是分析器调用分词器。在Lemon,分词器调用分析器; (2)Lemon不会使用全局变量。而yacc与bison在分析器与分词器之间使用全局变量; (3)Lemon允许多个分析器同时运行,因为它是可重入的。而yacc与bison却不行。2、输入文件语法
Lemon的语法规则文件(grammar specification file)主要用于为分析器定义语法规则。此外,输入文件还包括其它一些有用的信息,使用的Lemon的大部分工作就是写语法文件。
2.1、终结符与非终结符(Terminals and Nonterminals)
终结符通常是大写的字符串(数字或字母)。非终结符是小写的字符串(数字或字母)。
2.2、语法规则(Grammar Rules)
每个语法规则由三部分构成:以非终结符开始,随后紧接着为“::=”,然后是终结符(或非终结)列表,规则以英文语句“.”结尾。如下:
expr ::= expr PLUS expr. expr ::= expr TIMES expr. expr ::= LPAREN expr RPAREN. expr ::= VALUE.
上例中,有一个非终结符“expr”,和5个终结符:“PLUS”、“TIMES”、“LPAREN”、“RPAREN”、和“VALUE”。
与yacc和bison一样,Lemon允许为规则添加C代码块,并由分析器进行规则规约时调用。如下:expr ::= expr PLUS expr. { printf("Doing an addition...\n"); } 为了使规则有用,语法动作(grammar actions)必须与相应的语法规则联系起来。在yacc和bison中,动作(action)中的“$$”代表左值,而“$1”、“$2”等则代表“::=”右边的位置相应为1、2等的终结符或非终结符的值。这是非常有用的,但是,却非常容易出错。例如:
expr -> expr PLUS expr { $$ = $1 + $3; }; 而Lemon通过为规则中的每个符号指定一个额外的符号名字(symbolic)达到相同的目的,然后在动作中使用这些符号名字。如下:
expr(A) ::= expr(B) PLUS expr(C). { A = B+C; } 2.3、优先级规则(Precedence Rules)
Lemon采用与yacc和bison相同的方法处理歧义性问题。移进—规约冲突,则选择移进;规约——规约冲突,则选择先出现的规则。
同样,Lemon也允许通过优先级规则来解决冲突。如下:%left AND.%left OR.%nonassoc EQ NE GT GE LT LE.%left PLUS MINUS.%left TIMES DIVIDE MOD.%right EXP NOT.
2.4、特殊指示符(Special Directives)
Lemon支持如下一些特殊指示符:
%code %default_destructor %default_type %destructor %extra_argument %include %left %name %nonassoc %parse_accept %parse_failure %right %stack_overflow %stack_size %start_symbol %syntax_error %token_destructor %token_prefix %token_type %type
%code
%code表示将一段C/C++代码添加到输出文件的尾部。它主要用于包含一些动作例程(action routines)或者词法器的部分代码。%default_type
如果没有在%type中为非终结符指定数据类型,则default_type指定非终结符的数据类型。%destructor
为非终结符指定一个资源释放器(destructor)(%token_destructor为终结符指定资源释放器)。当非终结符从分析栈中弹出时,释放器就会被调用,以释放其占用的资源。包括如下情况: (1)一个规则发生规约,而非终结符的右边却没有C代码; (2)在错误处理中,出栈操作; (3)ParseFree函数返回。 释放器可以做任何操作,但是它主要用来释放非终结符占用的内存或其它资源。例:%type nt { void*}%destructor nt { free($$); }nt(A) ::= ID NUM. { A = malloc( 100 ); } 在例子中,“nt”的数据类型为“void *”。当“nt”的规则发生规约时,为非终结符通过malloc分配空间。之后,当非终结符从栈中弹出时,释放器会被调用,以释放malloc申请的内存。这可以避免内存泄漏。
注意,除非非终结符会在C动作代码中使用,否则,当非终结符从栈中弹出时,就会调用释放器释放资源。如果C代码使用非终结符,则由C代码保证资源的释放。%token_prefix
Lemon的生成文件会为每个终结符定义一个整数值。如下:#define AND 1#define MINUS 2#define OR 3#define PLUS 4
如果愿意,可以通过该指示符为#define的预处理符号加一个前缀。例如,可以在规则文件加上如下:
%token_prefix TOKEN_
则生成的文件的输出如下:
#define TOKEN_AND 1#define TOKEN_MINUS 2#define TOKEN_OR 3#define TOKEN_PLUS 4
%include
由该指示符指定的C代码会包含到生成的分析的顶部。你可以包含任意代码,Lemon会完全拷贝过去。%extra_argument
指示Parse函数中第四个参数。 Lemon本身不会做任何处理,但是相应的C代码可以使用该参数。%parse_accept
分析器进行语法分析成功时,执行的C代码。如:%parse_accept { printf("parsing complete!\n");} %stack_overflow
当分析器执行发生内部栈溢出时,会执行相应的动作。通常,可以输出错误消息,分析器不能继续执行,而必须重置。例如:%stack_overflow { fprintf(stderr,"Giving up. Parser stack overflow\n");} %name
默认情况下,Lemon生成的函数都以“Parse”开始,可以通过该指示符修改。例如:%name Abcde
这会导致Lemon生成的函数的名字如下:AbcdeAlloc(), AbcdeFree(), AbcdeTrace(), and Abcde().
%token_type与%type
这些指示符用于为分析器的栈中的终结符或非终结指定数据类型。所有终结符都必须是相同的类型,而与应该与Lemon生成的输出文件中的Parse()的第3个参数的类型一致。通常,可以将一个结构指针赋给终结符,如下:%token_type {Token*}
如果终结符的数据类型没有指定,默认为“int”。通常,每个非终结符都有各自的数据类型。例如,通常非终结符为指向的分析树的根结点的数据类型指针,该根结点包含非终结符的所有信息。例如:%type expr {Expr*} 3、SQLite语法规则分析
下面以SELECT语句简要的概述一下SQLite的语法规则。
3.1、SELECT语法
SELECT语法是SQL语句中最复杂的部分之一。而其它SQL语句,比如CREATE(DROP) TABLE、CREATE(DROP)INDEX、INSERT、DELETE、UPDATE相对来说比较简单。
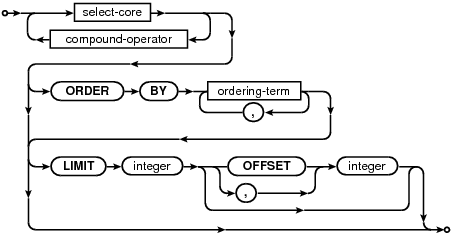
3.1.1、select-stmt
select的语法全图:
3.1.2、select-core
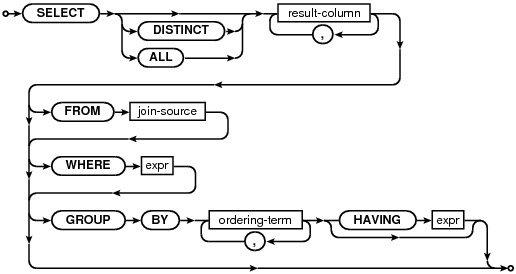
相应的语法规则:
cmd ::= select(X). { SelectDest dest = {SRT_Output, 0, 0, 0, 0}; sqlite3Select(pParse, X, &dest); sqlite3SelectDelete(pParse->db, X);}%type select {Select*} //select语句对应的结构体%destructor select {sqlite3SelectDelete(pParse->db, $$);}%type oneselect {Select*}%destructor oneselect {sqlite3SelectDelete(pParse->db, $$);}select(A) ::= oneselect(X). {A = X;}//...//简单SQL语句,可以分成以下几部分:输出列、from子句、where子句、group子句、having子句oneselect(A) ::= SELECT distinct(D) selcollist(W) from(X) where_opt(Y) groupby_opt(P) having_opt(Q) orderby_opt(Z) limit_opt(L). { A = sqlite3SelectNew(pParse,W,X,Y,P,Q,Z,D,L.pLimit,L.pOffset);} distinct
%type distinct { int}distinct(A) ::= DISTINCT. {A = 1;}distinct(A) ::= ALL. {A = 0;}distinct(A) ::= . {A = 0;} selcollist(输出结果列)
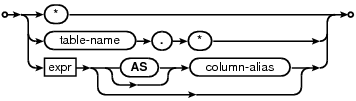
%type selcollist {ExprList*} //输出列对应的结构体%destructor selcollist {sqlite3ExprListDelete(pParse->db, $$);}%type sclp {ExprList*}%destructor sclp {sqlite3ExprListDelete(pParse->db, $$);}sclp(A) ::= selcollist(X) COMMA. {A = X;}sclp(A) ::= . {A = 0;}selcollist(A) ::= sclp(P) expr(X) as(Y). { A = sqlite3ExprListAppend(pParse, P, X.pExpr); if( Y.n>0 ) sqlite3ExprListSetName(pParse, A, &Y, 1); sqlite3ExprListSetSpan(pParse,A,&X);}selcollist(A) ::= sclp(P) STAR. { Expr *p = sqlite3Expr(pParse->db, TK_ALL, 0); A = sqlite3ExprListAppend(pParse, P, p);}selcollist(A) ::= sclp(P) nm(X) DOT STAR(Y). { Expr *pRight = sqlite3PExpr(pParse, TK_ALL, 0, 0, &Y); Expr *pLeft = sqlite3PExpr(pParse, TK_ID, 0, 0, &X); Expr *pDot = sqlite3PExpr(pParse, TK_DOT, pLeft, pRight, 0); A = sqlite3ExprListAppend(pParse,P, pDot);}// An option "AS " phrase that can follow one of the expressions that// define the result set, or one of the tables in the FROM clause.// AS语句%type as {Token}as(X) ::= AS nm(Y). {X = Y;}as(X) ::= ids(Y). {X = Y;}as(X) ::= . {X.n = 0;} from
from子句分以下几部分:
join-source:

single-source:

join-op:
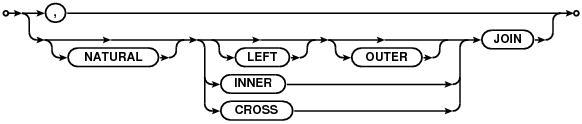
join-constraint:
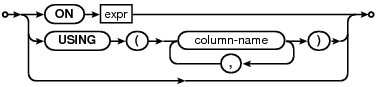
语法规则:
%type seltablist {SrcList*} //from子语对应的数据结构%destructor seltablist {sqlite3SrcListDelete(pParse->db, $$);}%type stl_prefix {SrcList*}%destructor stl_prefix {sqlite3SrcListDelete(pParse->db, $$);}%type from {SrcList*}%destructor from {sqlite3SrcListDelete(pParse->db, $$);}// A complete FROM clause. FROM子句//from(A) ::= . {A = sqlite3DbMallocZero(pParse->db, sizeof(*A));}from(A) ::= FROM seltablist(X). { A = X; sqlite3SrcListShiftJoinType(A);}// "seltablist" is a "Select Table List" - the content of the FROM clause// in a SELECT statement. "stl_prefix" is a prefix of this list.//stl_prefix(A) ::= seltablist(X) joinop(Y). { A = X; if( ALWAYS(A && A->nSrc>0) ) A->a[A->nSrc-1].jointype = (u8)Y;}stl_prefix(A) ::= . {A = 0;}//from后面的语句seltablist(A) ::= stl_prefix(X) nm(Y) dbnm(D) as(Z) indexed_opt(I) on_opt(N) using_opt(U). { A = sqlite3SrcListAppendFromTerm(pParse,X,&Y,&D,&Z,0,N,U); sqlite3SrcListIndexedBy(pParse, A, &I);}//数据库名%type dbnm {Token}dbnm(A) ::= . {A.z=0; A.n=0;}dbnm(A) ::= DOT nm(X). {A = X;}//全名%type fullname {SrcList*}%destructor fullname {sqlite3SrcListDelete(pParse->db, $$);}fullname(A) ::= nm(X) dbnm(Y). {A = sqlite3SrcListAppend(pParse->db,0,&X,&Y);}//join语句%type joinop { int}%type joinop2 { int}joinop(X) ::= COMMA|JOIN. { X = JT_INNER; }joinop(X) ::= JOIN_KW(A) JOIN. { X = sqlite3JoinType(pParse,&A,0,0); }joinop(X) ::= JOIN_KW(A) nm(B) JOIN. { X = sqlite3JoinType(pParse,&A,&B,0); }joinop(X) ::= JOIN_KW(A) nm(B) nm(C) JOIN. { X = sqlite3JoinType(pParse,&A,&B,&C); }//on语句%type on_opt {Expr*}%destructor on_opt {sqlite3ExprDelete(pParse->db, $$);}on_opt(N) ::= ON expr(E). {N = E.pExpr;}on_opt(N) ::= . {N = 0;}// Note that this block abuses the Token type just a little. If there is// no "INDEXED BY" clause, the returned token is empty (z==0 && n==0). If// there is an INDEXED BY clause, then the token is populated as per normal,// with z pointing to the token data and n containing the number of bytes// in the token.//// If there is a "NOT INDEXED" clause, then (z==0 && n==1), which is // normally illegal. The sqlite3SrcListIndexedBy() function // recognizes and interprets this as a special case.//index by语句(似乎不属于SQL92标准)%type indexed_opt {Token}indexed_opt(A) ::= . {A.z=0; A.n=0;}indexed_opt(A) ::= INDEXED BY nm(X). {A = X;}indexed_opt(A) ::= NOT INDEXED. {A.z=0; A.n=1;}//using语句%type using_opt {IdList*}%destructor using_opt {sqlite3IdListDelete(pParse->db, $$);}using_opt(U) ::= USING LP inscollist(L) RP. {U = L;}using_opt(U) ::= . {U = 0;} order by
%type orderby_opt {ExprList*}%destructor orderby_opt {sqlite3ExprListDelete(pParse->db, $$);}%type sortlist {ExprList*}%destructor sortlist {sqlite3ExprListDelete(pParse->db, $$);}%type sortitem {Expr*}%destructor sortitem {sqlite3ExprDelete(pParse->db, $$);}//order by语句orderby_opt(A) ::= . {A = 0;}orderby_opt(A) ::= ORDER BY sortlist(X). {A = X;}sortlist(A) ::= sortlist(X) COMMA sortitem(Y) sortorder(Z). { A = sqlite3ExprListAppend(pParse,X,Y); if( A ) A->a[A->nExpr-1].sortOrder = (u8)Z;}sortlist(A) ::= sortitem(Y) sortorder(Z). { A = sqlite3ExprListAppend(pParse,0,Y); if( A && ALWAYS(A->a) ) A->a[0].sortOrder = (u8)Z;}sortitem(A) ::= expr(X). {A = X.pExpr;}//顺序%type sortorder { int}sortorder(A) ::= ASC. {A = SQLITE_SO_ASC;}sortorder(A) ::= DESC. {A = SQLITE_SO_DESC;}sortorder(A) ::= . {A = SQLITE_SO_ASC;} group by
%type groupby_opt {ExprList*}%destructor groupby_opt {sqlite3ExprListDelete(pParse->db, $$);}groupby_opt(A) ::= . {A = 0;}groupby_opt(A) ::= GROUP BY nexprlist(X). {A = X;} having
%type having_opt {Expr*}%destructor having_opt {sqlite3ExprDelete(pParse->db, $$);}having_opt(A) ::= . {A = 0;}having_opt(A) ::= HAVING expr(X). {A = X.pExpr;} limit
%type limit_opt { struct LimitVal}// The destructor for limit_opt will never fire in the current grammar.// The limit_opt non-terminal only occurs at the end of a single production// rule for SELECT statements. As soon as the rule that create the // limit_opt non-terminal reduces, the SELECT statement rule will also// reduce. So there is never a limit_opt non-terminal on the stack // except as a transient. So there is never anything to destroy.////%destructor limit_opt {// sqlite3ExprDelete(pParse->db, $$.pLimit);// sqlite3ExprDelete(pParse->db, $$.pOffset);//}limit_opt(A) ::= . {A.pLimit = 0; A.pOffset = 0;}limit_opt(A) ::= LIMIT expr(X). {A.pLimit = X.pExpr; A.pOffset = 0;}limit_opt(A) ::= LIMIT expr(X) OFFSET expr(Y). {A.pLimit = X.pExpr; A.pOffset = Y.pExpr;}limit_opt(A) ::= LIMIT expr(X) COMMA expr(Y). {A.pOffset = X.pExpr; A.pLimit = Y.pExpr;}